Manejo de datos con Pandas
Vista de la librería para la manipulación y el análisis de datos



- 1. Resumen
- 2. ¿Qué es Pandas?
- 3. Estructuras de datos de Pandas
- 4. Exploración de un DataFrame
- 5. Adición de columnas
- 6. Eliminación de columnas
- 7. Operaciones sobre DataFrames
- 8. Transpuesta
- 9. Conversión a Numpy
- 10. Lectura de datos de fuentes externas
- 11. Indexación en DataFrames
- 11.1. Indexación por de columnas
- 11.2. Indexación de filas por posiciones
- 11.3. Indexación de filas por etiquetas
- 11.4. Selección de una porción del DataFrame mediante posiciones
- 11.5. Selección de una porción del DataFrame mediante etiquetas
- 11.6. Indexación por función lambda
- 11.7. Indexación aleatoria
- 12. Unión de DataFrames
- 13. Datos faltantes (NaN)
- 14. Series temporales
- 15. Datos categóricos
- 16. Gráficos
Vamos a ver una pequeña introducción a la librería de manipulación y analisis de datos Pandas. Con ella podremos manejar y procesar datos tabulares que nos ayudará para poder operar con ellos y obtener información de una manera muy valiosa
![]()
Pandas es una librería de Python que está diseñada para que el trabajo con datos relacionales o etiquetados sea fácil e intuitivo
Pandas está diseñado para muchos tipos diferentes de datos:
- Datos tabulares con columnas de tipos heterogéneos, como en una tabla SQL o una hoja de cálculo de Excel
- Datos de series de tiempo ordenados y desordenados (no necesariamente de frecuencia fija).
- Datos matriciales arbitrarios (homogéneos o heterogéneos) con etiquetas de fila y columna
- Cualquier otra forma de conjuntos de datos observacionales/estadísticos. No es necesario etiquetar los datos en absoluto para colocarlos en una estructura de datos de pandas.
Las dos estructuras de datos principales de Pandas son las Series (unidimensional) y los DataFrames (bidimensional). Pandas está construido sobre NumPy y está destinado a integrarse bien dentro de un entorno informático científico con muchas otras bibliotecas de terceros.
Para los científicos de datos, el trabajo con datos generalmente se divide en varias etapas: recopilar y limpiar datos, analizarlos/modelarlos y luego organizar los resultados del análisis en una forma adecuada para trazarlos o mostrarlos en forma de tabla. Pandas es la herramienta ideal para todas estas tareas.
Otra característica es que pandas es rápido, muchos de los algoritmos de bajo nivel se han construido en C
Generalmente a la hora de importar Pandas se suele importar con el alias de pd
import pandas as pd
print(pd.__version__)
En Pandas existen dos tipos de estructuras de datos: las Series y los DataFrames
El tipo de dato Serie es una matriz etiquetada unidimensional capaz de contener cualquier tipo de datos (enteros, cadenas, números de punto flotante, objetos Python, etc.). Están divididas en índices.
Para crear un tipo de dato Serie la forma más común es
serie = pd.Series(data, index=index)
Donde data puede ser
- Un diccionario
- Una lista o tupla
- Un ndarray de Numpy
- Un valor escalar
Como uno de los tipos de datos puede ser un ndarray de Numpy, importamos Numpy para poder usarlo
import numpy as np
diccionario = {"b": 1, "a": 0, "c": 2}
serie = pd.Series(diccionario)
serie
Si se pasa un índice, se extraerán los valores de los datos correspondientes a las etiquetas del índice. Si no existen se crean como NaN (not a number)
diccionario = {"b": 1, "a": 0, "c": 2}
serie = pd.Series(diccionario, index=["b", "c", "d", "a"])
serie
Si los datos provienen de una lista o tupla y no se pasa ningún índice, se creará uno con valores [0, ..., len(data)-1]
serie = pd.Series([1, 2, 3, 4])
serie
Si se pasa un índice, este debe tener la misma longitud que los datos
serie = pd.Series([1, 2, 3, 4], index=["a", "b", "c", "d"])
serie
Si los datos provienen de un ndarray y no se pasa ningún índice, se creará uno con valores [0, ..., len(data)-1]
serie = pd.Series(np.random.randn(5))
serie
Si se pasa un índice, este debe tener la misma longitud que los datos
serie = pd.Series(np.random.randn(5), index=["a", "b", "c", "d", "e"])
serie
Si se crea la serie desde un escalar, se creará con un único item
serie = pd.Series(5.0)
serie
Si se quieren crear más items en la serie, hay que pasarle el índice con el número de items que se quiere, de esta manera todos los items tendrán el valor del escalar
serie = pd.Series(5.0, index=["a", "b", "c", "d", "e"])
serie
Al igual que con Numpy, podemos realizar operaciones con todos los elementos de una serie, sin tener que hacer una iteracción por cada uno de ellos
serie = pd.Series(5.0, index=["a", "b", "c", "d", "e"])
print(f"serie:\n{serie}")
print(f"\nserie + serie =\n{serie + serie}")
serie = pd.Series(5.0, index=["a", "b", "c", "d", "e"])
print(f"serie:\n{serie}")
print(f"\nexp(serie) =\n{np.exp(serie)}")
Una diferencia entre Series y ndarrays es que las operaciones entre Series alinean automáticamente los datos según sus etiquetas. Por lo tanto, se pueden escribir cálculos sin tener en cuenta si las Series involucradas tienen las mismas etiquetas. Si no se encuentra una etiqueta en una Serie u otra, el resultado se marcará como faltante (NaN).
serie = pd.Series(5.0, index=["a", "b", "c", "d", "e"])
print(f"serie:\n{serie}")
print(f"\nserie[1:] + serie[:-1] =\n{serie[1:] + serie[:-1]}")
Uno de los atributos de las Series es name, el cual corresponde al nombre que tendrán cuando se añadan a un DataFrame. Por el camino contrario, cuando se obtiene una serie de un DataFrame, esta serie tendrá como nombre el que tenía en el DataFrame
serie = pd.Series(np.random.randn(5), name="aleatorio")
serie
Se puede cambiar el nombre de una serie mediante el méteodo rename()
serie = serie.rename("random")
serie
Un DataFrame es una estructura de datos etiquetada y bidimensional, con columnas de tipos potencialmente diferentes, es decir, en una columna puede haber datos de tipo entero, en otra columna datos de tipo string, etc. Puede pensar en ello como una hoja de cálculo o una tabla SQL, o un diccionario de objetos Series.
Es el objeto pandas más utilizado. Al igual que las Series, los DataFrames aceptan muchos tipos diferentes de entrada:
Junto con los datos, opcionalmente puede pasar argumentos de índice (etiquetas de fila) y columnas (etiquetas de columna). Si pasa un índice y/o columnas, está garantizando el índice y/o columnas del DataFrame resultante. Por lo tanto, un diccionario de Series más un índice específico descartará todos los datos que no coincidan con el índice pasado
Si no se pasan las etiquetas de los ejes, se construirán a partir de los datos de entrada basándose en reglas de sentido común.
Si se pasa un diccionario con Series se creará el DataFrame con tantas columnas como Series tenga el diccionario
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0]),
"dos": pd.Series([4.0, 5.0, 6.0, 7.0])
}
dataframe = pd.DataFrame(diccionario)
dataframe
Si cada una de las Series tiene índices definidos, el DataFrame resultante será la unión de estos índices
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"dos": pd.Series([4.0, 5.0, 6.0, 7.0], index=["a", "b", "c", "d"])
}
dataframe = pd.DataFrame(diccionario)
dataframe
dataframe = pd.DataFrame(diccionario, index=["d", "b", "a"])
dataframe
Si se le pasa las columnas aparecerán en el orden pasado
dataframe = pd.DataFrame(diccionario, columns=["dos", "tres"])
dataframe
Todos los ndarrays o listas deben tener la misma longitud. Si se pasa un índice, también debe tener la misma longitud que los ndarrays o listas
diccionario = {
"uno": [1.0, 2.0, 3.0, 4.0],
"dos": [4.0, 3.0, 2.0, 1.0]
}
dataframe = pd.DataFrame(diccionario)
dataframe
Si se pasa un índice tiene que tener la misma longitud que el número de filas de la matriz y si se pasan las columnas tienen que tener la misma longitud que las columnas de la matriz
matriz = np.array([[1, 3], [2, 2], [3, 1]])
dataframe = pd.DataFrame(matriz, index=["a", "b", "c"], columns=["columna1", "columna2"])
dataframe
lista = [{"a": 1, "b": 2}, {"a": 5, "b": 10, "c": 20}]
dataframe = pd.DataFrame(lista)
dataframe
diccionario = {
("a", "b"): {("A", "B"): 1, ("A", "C"): 2},
("a", "a"): {("A", "C"): 3, ("A", "B"): 4},
("a", "c"): {("A", "B"): 5, ("A", "C"): 6},
("b", "a"): {("A", "C"): 7, ("A", "B"): 8},
("b", "b"): {("A", "D"): 9, ("A", "B"): 10},
}
dataframe = pd.DataFrame(diccionario)
dataframe
El resultado será un DataFrame con el mismo índice que la Serie de entrada, y con una columna cuyo nombre es el nombre original de la Serie (solo si no se proporciona otro nombre de columna).
diccionario = {"b": 1, "a": 0, "c": 2}
serie = pd.Series(diccionario)
dataframe = pd.DataFrame(serie)
dataframe
Cuando un DataFrame es muy grande no se puede representar entero
california_housing_train = pd.read_csv("/content/sample_data/california_housing_train.csv")
california_housing_train
Por lo que es muy útil tener métodos para explorarlo y obtener información de manera rápida
Para ver las primeras filas y hacerse una ídea de cómo es el DataFrame existe el metodo head(), que por defecto muestra las primeras 5 filas del DataFrame. Si se quiere ver un número distinto de filas introducirlo mediante el atributo n
california_housing_train.head(n=10)
Si lo que se quiere es ver las últimas filas se puede usar el método tail(), mediante el atributo n se elige cuantas filas mostrar
california_housing_train.tail()
Otro método muy util es info() que nos da información del DataFrame
california_housing_train.info()
Se pueden obtener los índices y las columnas de un DataFrame mediante los métodos index y columns
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"dos": pd.Series([4.0, 5.0, 6.0, 7.0], index=["a", "b", "c", "d"])
}
dataframe = pd.DataFrame(diccionario)
indices = dataframe.index
columnas = dataframe.columns
print(f"El DataFrame tiene los índices\n\t{indices}\n")
print(f"El DataFrame tiene las columnas\n\t{columnas}")
El método describe() muestra un resumen estadístico rápido de los datos del DataFrame
california_housing_train = pd.read_csv("/content/sample_data/california_housing_train.csv")
california_housing_train.describe()
Se pueden ordenar alfabéticamente las filas de un DataFrame mediante el método sort_index()
california_housing_train = pd.read_csv("/content/sample_data/california_housing_train.csv")
california_housing_train.sort_index().head()
Como en este caso las filas ya estaban ordenadas establecemos ascending=False para que el orden sea al revés
california_housing_train.sort_index(ascending=False).head()
Si lo que se quiere son ordenar las columnas hay que introducir index=1 ya que por defecto es 0
california_housing_train.sort_index(axis=1).head()
Si lo que queremos es ordenar el DataFrame a través de una columna determinada tenemos que usar el método sort_values() e indicarle la etiqueta de la columna sobre la que se quiere ordenar
california_housing_train.sort_values('median_house_value')
Se pueden obtener estadísticas del DataFrame, como la media, la moda, la desviación estandar
california_housing_train = pd.read_csv("/content/sample_data/california_housing_train.csv")
print(f"media:\n{california_housing_train.mean()}")
print(f"\n\ndesviación estandar:\n{california_housing_train.std()}")
Si se quieren obtener las estadísticas sobre las filas y no sobre las comlumnas hay que indicarlo mediante axis=1
california_housing_train = pd.read_csv("/content/sample_data/california_housing_train.csv")
print(f"media:\n{california_housing_train.mean(axis=1)}")
print(f"\n\ndesviación estandar:\n{california_housing_train.std(axis=1)}")
Otra cosa útil que se puede obtener de los DataFrames es por ejemplo el número de veces que se repite cada item de una columna
california_housing_train["total_rooms"].value_counts()
Por ejemplo podemos ver que hay un total de 16 casas con 1582 habitaciones!
Se pueden añadir columnas facilmente como operaciones de otras columnas
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0]),
"dos": pd.Series([4.0, 5.0, 6.0, 7.0])
}
dataframe = pd.DataFrame(diccionario)
dataframe["tres"] = dataframe["uno"] + dataframe["dos"]
dataframe["flag"] = dataframe["tres"] > 7.0
dataframe
También se pueden añadir columnas indicando qué valor tendrán todos sus items
dataframe["constante"] = 8.0
dataframe
Si se añade una Serie que no tiene el mismo número de índices que el DataFrame, esta se ajustará al número de índices del DatFrame
dataframe["Menos indices"] = dataframe["uno"][:2]
dataframe
Con los métodos anteriores la columna se añadía al final, pero si se quiere añadir la columna en una posición determinda se puede usar el método insert().
Por ejemplo, si se quiere añadir una columna en la posición 3 (teniendo en cuenta que se empieza a contar desde la posición 0), que el nombre de la columna sea columna insertada y que su valor sea el doble que el de la columna tres se haría de la siguiente manera
dataframe.insert(loc=3, column="columna insertada", value=dataframe["tres"]*2)
dataframe
Si se quiere añadir más de una columna por comando se puede usar el método assign()
dataframe = dataframe.assign(
columna_asignada1 = dataframe["uno"] * dataframe["tres"],
columna_asignada2 = dataframe["dos"] * dataframe["tres"],
)
dataframe
Se puede eliminar una columna determinada mediante el método pop()
dataframe.pop("constante")
dataframe
O mediante del
del dataframe["flag"]
dataframe
Se pueden realizar operaciones sobre los DataFrames al igual que se podía hacer con Numpy
dataframe[ ["uno", "dos", "tres"] ] * 2
np.exp(dataframe[ ["uno", "dos", "tres"] ])
Si se quiere realizar operaciones más complejas se puede utilizar el método apply()
dataframe = dataframe.apply(lambda x: x.max() - x.min())
dataframe
Se puede hacer la transpuesta de un DataFrame mediante el método T
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0], index=["fila a", "fila b", "fila c"]),
"dos": pd.Series([4.0, 5.0, 6.0], index=["fila a", "fila b", "fila c"])
}
dataframe = pd.DataFrame(diccionario)
dataframe["tres"] = dataframe["uno"] + dataframe["dos"]
dataframe["flag"] = dataframe["tres"] > 7.0
dataframe.T
Si se quiere convertir una Serie o DataFrame a Numpy se puede usar el método to_numpy() o usar la función np.asarray()
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0], index=["fila a", "fila b", "fila c"]),
"dos": pd.Series([4.0, 5.0, 6.0], index=["fila a", "fila b", "fila c"])
}
dataframe = pd.DataFrame(diccionario)
dataframe["tres"] = dataframe["uno"] + dataframe["dos"]
dataframe["flag"] = dataframe["tres"] > 7.0
dataframe
matriz_np = dataframe.to_numpy()
matriz_np
matriz_np = np.asarray(dataframe)
matriz_np
Este ejemplo no es el más indicado, ya que mezcla números con booleanos, y como ya explicamos en el anterior posst Cálculo matricial con Numpy, todos los elementos de un ndarray tienen que ser del mismo tipo.
En este caso estamos mezclando números con booleanos, por lo que para solucionarlo Numpy los convierte todos a objetos
Para solucionar esto nos quedamos solo con los números y los convertimos a un ndarray
matriz_np = dataframe[ ["uno", "dos", "tres"] ].to_numpy()
matriz_np, matriz_np.dtype
Ahora se puede ver que se ha creado un ndarray donde todos los datos son de tipo float
Una de las mayores fortalezas de Pandas es poder leer datos de archivos, por lo que no es necesario crearse un DataFrame con los datos que se quieren procesar, sino que se pueden leer de un archivo
De la misma manera que se pueden crear DataFrames de archivos externos, también se pueden guardar DataFrames en archivos, para así crearte tu propio set de datos, configurarlo de la manera que quieras y guardarlo en un archivo para poder usarlo más adelante
En la siguiente tabla se muestran las funciones para leer y escribir archivos de distintos formatos
| Fromato | Tipo de archivo | Función de lectura | Función de escritura |
|---|---|---|---|
| texto | CSV | read_csv | to_csv |
| texto | Fixed-Width Text File | read_fwf | |
| texto | JSON | read_json | to_json |
| texto | HTML | read_html | to_html |
| texto | Local clipboard | read_clipboard | to_clipboard |
| binary | MS Excel | read_excel | to_excel |
| binary | OpenDocument | read_excel | |
| binary | HDF5 Format | read_hdf | to_hdf |
| binary | Feather Format | read_feather | to_feather |
| binary | Parquet Format | read_parquet | to_parquet |
| binary | ORC Format | read_orc | |
| binary | Msgpack | read_msgpack | to_msgpack |
| binary | Stata | read_stata | to_stata |
| binary | SAS | read_sas | |
| binary | SPSS | read_spss | |
| binary | Python Pickle Format | read_pickle | to_pickle |
| SQL | SQL | read_sql | to_sql |
| SQL | Google BigQuery | read_gbq | to_gbq |
Hay muchas maneras de indexar en los DatFrames,
fechas = pd.date_range('1/1/2000', periods=8)
dataframe = pd.DataFrame(np.random.randn(8, 4), index=fechas, columns=['A', 'B', 'C', 'D'])
dataframe
Para seleccionar columnas dentro de un DataFrame lo podemos hacer seleccionando la columna entre corchetes [], o indicando la columna como si fuese un método del DataFrame
dataframe['A']
dataframe.A
Si se quiere unas filas determinadas se pasan mediante una lista
dataframe[ ['A', 'B'] ]
Se puede seleccionar un rango de filas de un DataFrame de la siguiente manera
dataframe[0:3]
Si solo se quiere seleccionar una sola fila, hay que indicar un rago de filas que incluya solo a esa, si por ejemplo se quiere seleccionar la fila numero 1
dataframe[1:2]
Otro método para seleccionar una fila por su posicione es el método iloc[]
dataframe.iloc[0:3]
Si se quieren unas filas determinadas se pasa una lista con sus posiciones
dataframe.iloc[ [0, 2, 4] ]
Para seleccionar una fila por sus etiquetas podemos usar el método loc[]
dataframe.loc['2000-01-01']
Si se quiere seleccionar un rango de filas podemos indexarlas mediante los dos puntos :
dataframe.loc['2000-01-01':'2000-01-03']
Si se quiere unas filas determinadas se pasan mediante una lista
dataframe.loc[ ['2000-01-01', '2000-01-03', '2000-01-05'] ]
dataframe.iloc[0:3, 0:2]
Si se quieren unas filas y columnas determinadas se pasan listas con las posiciones deseadas
dataframe.iloc[ [0, 2, 4], [0, 2] ]
dataframe.loc['2000-01-01':'2000-01-03', 'A':'B']
Si se quieren unas filas y columnas determinadas se pasan listas con las etiquetas deseadas
dataframe.loc[ ['2000-01-01', '2000-01-03', '2000-01-05'], ['A', 'C'] ]
Se pueden seleccionar datos de un DataFrame que cumplan una condición dada por una función lambda
dataframe.loc[lambda dataframe:dataframe['A']>0.2]
Mediante el método sample() obtendremos una fila aleatoria del DataFrame
dataframe.sample()
Si queremos más de una muestra lo indicamos con el atributo n
dataframe.sample(n=3)
Si lo que se quiere son columnas aleatorias hay que indicarlo mediante axis=1
dataframe.sample(axis=1)
Si se quiere un único item del DataFrame hay que llamar dos veces al método sample()
dataframe.sample(axis=1).sample()
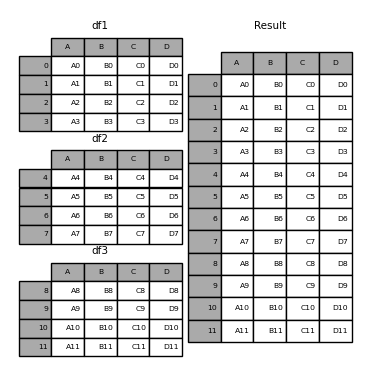
Para concatenar varios DataFrames usamos la el método concat(), donde se le pasará una lista con los DataFrames que se quiere unir
dataframe1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3])
dataframe2 = pd.DataFrame(
{
"A": ["A4", "A5", "A6", "A7"],
"B": ["B4", "B5", "B6", "B7"],
"C": ["C4", "C5", "C6", "C7"],
"D": ["D4", "D5", "D6", "D7"],
},
index=[4, 5, 6, 7])
dataframe3 = pd.DataFrame(
{
"A": ["A8", "A9", "A10", "A11"],
"B": ["B8", "B9", "B10", "B11"],
"C": ["C8", "C9", "C10", "C11"],
"D": ["D8", "D9", "D10", "D11"],
},
index=[8, 9, 10, 11])
dataframe = pd.concat([dataframe1, dataframe2, dataframe3])
print(f"dataframe1:\n{dataframe1}")
print(f"dataframe2:\n{dataframe2}")
print(f"dataframe3:\n{dataframe3}")
print(f"\ndataframe:\n{dataframe}")
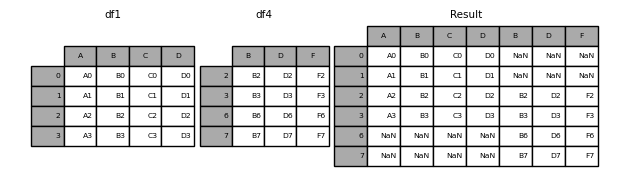
Si se hubiera querido hacer la concatenación a lo largo de las columnas habría que haber introducido la variable axis=1
Hay dos maneras de hacer la concatenación, cogiendo todos los índices de los DataFrames o cogiendo solo los que coinciden, esto se determina mediante la variable join, que admite los valores 'outer' (por defecto) (coge todos los índices) o 'inner' (solo los que coinciden)
Veamos un ejemplo de 'outer'
dataframe1 = pd.DataFrame(
{
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"],
},
index=[0, 1, 2, 3])
dataframe4 = pd.DataFrame(
{
"B": ["B2", "B3", "B6", "B7"],
"D": ["D2", "D3", "D6", "D7"],
"F": ["F2", "F3", "F6", "F7"],
},index=[2, 3, 6, 7])
dataframe = pd.concat([dataframe1, dataframe4], axis=1)
print(f"dataframe1:\n{dataframe1}")
print(f"dataframe2:\n{dataframe4}")
print(f"\ndataframe:\n{dataframe}")
Veamos un ejemplo de 'inner'
dataframe = pd.concat([dataframe1, dataframe4], axis=1, join="inner")
print(f"dataframe1:\n{dataframe1}")
print(f"dataframe2:\n{dataframe4}")
print(f"\ndataframe:\n{dataframe}")

En un DataFrame puede haber algunos datos faltantes, Pandas los representa como np.nan
diccionario = {
"uno": pd.Series([1.0, 2.0, 3.0]),
"dos": pd.Series([4.0, 5.0, 6.0, 7.0])
}
dataframe = pd.DataFrame(diccionario)
dataframe
Para no tener filas con datos faltantes se pueden eliminar estas
dataframe.dropna(how="any")
dataframe.dropna(axis=1, how='any')
pd.isna(dataframe)
dataframe.fillna(value=5.5, inplace=True)
dataframe
inplace=True se modifica el DataFrame sobre el que se está operando, así no hace falta escribir
Python
dataframe = dataframe.fillna(value=5.5)
Pandas ofrece la posibilidad de trabajar con series temporales. Por ejemplo creamos una Serie de 100 datos aleatorios cada segundo desde el 01/01/2021
indices = pd.date_range("1/1/2021", periods=100, freq="S")
datos = np.random.randint(0, 500, len(indices))
serie_temporal = pd.Series(datos, index=indices)
serie_temporal
Esta funcionalidad de Pandas es muy potente, por ejemplo, podemos tener un conjunto de datos en unas horas determinadas de un uso horario y cambiarlas a otro uso
horas = pd.date_range("3/6/2021 00:00", periods=10, freq="H")
datos = np.random.randn(len(horas))
serie_horaria = pd.Series(datos, horas)
serie_horaria
Localizamos los datos en un uso horario
serie_horaria_utc = serie_horaria.tz_localize("UTC")
serie_horaria_utc
Y ahora las podemos cambiar a otro uso
serie_horaria_US = serie_horaria_utc.tz_convert("US/Eastern")
serie_horaria_US
Pandas ofrece la posibilidad de añadir datos categóricos en un DatFrame. Supongamos el siguente DataFrame
dataframe = pd.DataFrame(
{"id": [1, 2, 3, 4, 5, 6], "raw_grade": ["a", "b", "b", "a", "a", "e"]}
)
dataframe
Podemos convertir los datos de la columna raw_rade a datos categóricos mediante el método astype()
dataframe['grade'] = dataframe["raw_grade"].astype("category")
dataframe
Las columnas raw_grade y grade parecen iguales, pero si vemos la información del DataFrame podemos ver que no es así
dataframe.info()
Se puede ver que la columna grade es de tipo categórico
Pandas ofrece la posibilidad de representar los datos de nuestros DataFrames en gráficos para poder obtener una mejor representación de ello. Para ello hace uso de la librería matplotlib que veremos en el siguiente post
Para representar los datos en una gráfica la manera más fácil es usar el método plot()
serie = pd.Series(np.random.randn(1000), index=pd.date_range("1/1/2000", periods=1000))
serie = serie.cumsum()
serie.plot()

En el caso de tener un DataFrame el método plot() representará cada una de las columnas del DataFrame
dataframe = pd.DataFrame(
np.random.randn(1000, 4), index=ts.index, columns=["A", "B", "C", "D"]
)
dataframe = dataframe.cumsum()
dataframe.plot()

Hay más métodos de crear gráficos, como el diagrama de barras vertical mediante plot.bar()
dataframe = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"])
dataframe.plot.bar()

Si queremos apilar las barras lo indicamos mediante la variable stacked=True
dataframe.plot.bar(stacked=True)

Para crear un diagrama de barras horizontal usamos plot.barh()
dataframe.plot.barh()

Si queremos apilar las barras lo indicamos mediante la variable stacked=True
dataframe.plot.barh(stacked=True)

Para crear un histograma usamos plot.hist()
dataframe = pd.DataFrame(
{
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000),
"c": np.random.randn(1000) - 1,
}
)
dataframe.plot.hist(alpha=0.5)

Si queremos apilar las barras lo indicamos mediante la variable stacked=True
dataframe.plot.hist(alpha=0.5, stacked=True)

Si queremos añadir más columnas, es decir, si queremos que el histograma sea más informativo o preciso, lo indicamos mediante la variable bins
dataframe.plot.hist(alpha=0.5, stacked=True, bins=20)

Para crear un diagrama de velas usamos plot.box()
dataframe = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"])
dataframe.plot.box()

Para crear un gráfico de áreas usamos plot.area()
dataframe.plot.area()

Para crear un diagrama de dispersión usamos plot.scatter(), donde hay que indicar las variables x e y del diagrama
dataframe.plot.scatter(x='A', y='B')

Para crear un gráfico de contenedor hexagonal usamos plot.hexbin(), donde hay que indicar las variables x e y del diagrama y el tamaño de la malla mediante gridsize
dataframe = pd.DataFrame(np.random.randn(1000, 2), columns=["a", "b"])
dataframe["b"] = dataframe["b"] + np.arange(1000)
dataframe.plot.hexbin(x="a", y="b", gridsize=25)
